The NVIDIA H100 GPU
Last updated

Copyright Continuum Labs - 2023
Last updated
The H100 is a graphics processing unit (GPU) chip manufactured by Nvidia.
It is currently the most powerful GPU chip on the market and is designed specifically for artificial intelligence (AI) applications. Each chip costs around $US75,000.
The H100 is currently in high demand due to its powerful performance and its ability to accelerate AI applications.
The H-100 is built around the Hopper architecture - the latest GPU architecture developed by NVIDIA, named after the renowned computer scientist Grace Hopper.
It succeeds the previous Ampere architecture and introduces various improvements and new features to enhance performance and efficiency.
The Hopper architecture represents a lift in GPU technology, enabling faster processing, improved memory bandwidth, and more advanced features compared to its predecessor.
It lays the foundation for the H100 GPU to deliver exceptional performance across a wide range of AI, high performance computing, and data analytics workloads.
TSMC (Taiwan Semiconductor Manufacturing Company) is a leading semiconductor foundry that manufactures chips for various companies, including NVIDIA.
The custom 4N process is a specialised manufacturing process developed by TSMC specifically for NVIDIA's H100 GPU, optimised for high performance and energy efficiency.
The custom 4N process allows NVIDIA to pack more transistors into a smaller area, enabling higher clock speeds and improved power efficiency compared to previous manufacturing processes.
This advanced process technology is critical for achieving the H100's performance.
Transistors are the basic building blocks of modern electronics, and the number of transistors on a chip is a key indicator of its complexity and potential performance. The die size refers to the physical dimensions of the chip.
The H100 GPU features an astonishing 80 billion transistors, which is a massive increase compared to the previous generation A100 GPU, which had 54.2 billion transistors.
To put this into perspective, the H100's transistor count is more than the combined population of several countries.
The large 814 mm² die size enables the integration of more processing units and memory interfaces, contributing to the H100's exceptional performance.
SMs are the primary processing units within an NVIDIA GPU, responsible for executing parallel threads and performing complex computations.
SMs (Streaming Multiprocessors) are the fundamental processing units that perform the parallel computations. They are similar to the cores in a CPU, but are designed specifically for parallel processing.
SMs are composed of several types of arithmetic units, including INT32 units for mixed-precision integer operations, FP32 units (also known as CUDA cores) for single-precision floating-point operations, and FP64 units for double-precision floating-point operations.
Each SM contains a set of CUDA Cores (for general-purpose computing), Tensor Cores (for AI and deep learning), and RT Cores (for ray tracing).
The H100 GPU boasts 132 SMs, a significant increase from the A100's 108 SMs.
Each SM in the H100 is equipped with 128 FP32 CUDA Cores, 4 fourth-generation Tensor Cores, and 6 third-generation RT Cores.
This substantial increase in the number and capability of the SMs allows the H100 to handle more complex and demanding workloads with improved efficiency.
The picture below shows the SM architecture. The smallest boxes here with “INT32'“ or “FP32” or “FP64” represent the hardware or ‘execution units’ to perform single 32-bit integer, 32-bit floating point or 64-bit floating point operations.
So in this case we have thirty-two 32-bit floating point execution units, and sixteen each of the 32-bit integer and 64-bit float execution unit
You can see a large green box called Tensor Core. We will discuss that later on.
Tensor Cores are a key component of modern NVIDIA GPUs, and they work in conjunction with the other arithmetic units within the SMs (Streaming Multiprocessors) to deliver high-performance computing capabilities.
Tensor Cores are processing units designed for accelerating matrix multiplication and convolution operations, which are the foundation of deep learning and AI algorithms.
The fourth-generation Tensor Cores in the H100 introduce support for new precision formats and offer higher performance compared to the previous generation.
The H100's fourth-generation Tensor Cores deliver up to 6x higher performance than the A100's Tensor Cores, enabling faster training and inference of AI models.
They support a wide range of precision formats, including FP8, FP16, bfloat16, TF32, and FP64, allowing users to choose the optimal balance between precision and performance for their specific workloads.
Dynamic Programming (DP) is an algorithmic technique that solves complex problems by breaking them down into simpler sub-problems.
The solutions to these sub-problems are stored and reused, reducing the overall computational complexity.
The H100 GPU introduces DPX instructions, which accelerate the performance of DP algorithms by up to 7 times compared to the previous generation NVIDIA Ampere GPUs.
DPX instructions provide support for advanced fused operands in the inner loop of many DP algorithms, resulting in faster times-to-solution for applications in fields like , robotics ( for optimal route finding), and graph analytics.
Two essential keys to achieving high performance in parallel programs are data locality and asynchronous execution.
By moving program data as close as possible to the execution units, a programmer can exploit the performance that comes from having lower latency and higher bandwidth access to local data.
Asynchronous execution involves finding independent tasks to overlap with memory transfers and other processing. The goal is to keep all the units in the GPU fully used.
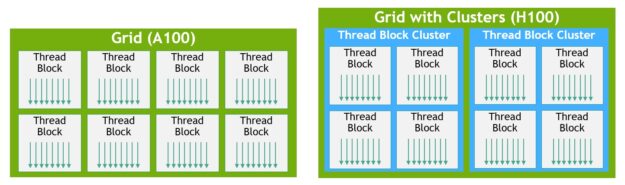
The NVIDIA Hopper adds an important new tier to the GPU programming hierarchy that exposes locality at a scale larger than a single thread block on a single SM.
The H100 introduces a new thread block cluster architecture that exposes control of locality at a granularity larger than a single thread block on a single SM.
A cluster is a group of thread blocks that are guaranteed to be concurrently scheduled onto a group of streaming multiprocessors (SMs), where the goal is to enable efficient cooperation of threads across multiple SMs - they are physically close together.
This allows for efficient cooperation of threads across multiple SMs.
The CUDA programming model has long relied on a GPU compute architecture that uses grids containing multiple thread blocks to leverage locality in a program.
Thread block clusters extend the CUDA programming model and add another level to the GPU’s physical programming hierarchy to include threads, thread blocks, thread block clusters, and grids.
The clusters in H100 run concurrently across SMs within a GPC.
In CUDA, thread blocks in a grid can optionally be grouped at kernel launch into clusters as shown below, and cluster capabilities can be leveraged from the CUDA cooperative_groups API.
A grid is composed of thread blocks in the legacy CUDA programming model as in A100, shown in the left half of the diagram. The NVIDIA Hopper Architecture adds an optional cluster hierarchy, shown in the right half of the diagram.
The H100 introduces new features to improve asynchronous execution and enable further overlap of memory copies with computation and other independent work:
Tensor Memory Accelerator (TMA)
The TMA is a new unit that efficiently transfers large blocks of data and multidimensional tensors between global memory and shared memory. It reduces addressing overhead and improves efficiency by supporting different tensor layouts, memory access modes, and reductions.
Asynchronous Transaction Barrier
This new type of barrier counts both thread arrivals and transactions (byte counts).
It allows threads to sleep until all other threads arrive and the sum of all transaction counts reaches an expected value, enabling more efficient synchronisation for asynchronous memory copies and data exchanges.
HBM (High Bandwidth Memory) is a type of high-performance memory that offers higher bandwidth and lower power consumption compared to traditional .
HBM3 is the latest generation of this type of memory technology.
The H100 GPU comes with up to 80GB of HBM3 memory, which is double the capacity of the A100's 40GB HBM2 memory.
HBM3 provides a memory bandwidth of up to 3 terabytes per second (3 Tb/s), enabling fast data transfer between the GPU and memory, which is crucial for memory-intensive workloads like AI training and scientific simulations.
To put this into perspective, 3 TB/s is equivalent to transferring the entire content of a 1TB hard drive in just 0.33 seconds.
MIG was a feature first introduced in NVIDIA's Ampere architecture and further enhanced in the Hopper architecture.
It allows a single physical GPU to be partitioned into multiple isolated instances, each with its own dedicated resources, such as compute units, memory, and cache.
With MIG, the H100 GPU can be divided into up to seven independent instances, providing flexibility and efficiency in resource allocation.
This feature is particularly useful in cloud and data centre environments, where multiple users or applications can share a single GPU, ensuring optimal utilisation and predictable performance.
MIG enables better resource management, improved security, and increased versatility in deploying GPU-accelerated workloads.
performance measures the GPU's ability to perform single-precision arithmetic operations, commonly used in scientific simulations, computer graphics, and some AI workloads.
TFLOPS (Tera Floating-Point Operations Per Second) is a unit that represents the number of floating-point operations the GPU can perform per second.
The H100's FP32 performance of 67 TFLOPS is a substantial increase from the A100's 19.5 TFLOPS, indicating a significant boost in raw computational power.
This high FP32 performance is for applications that require fast and precise single-precision calculations, enabling faster execution of complex simulations and rendering tasks.
Tensor performance refers to the GPU's capability to perform mixed-precision matrix multiplication and convolution operations, which are the backbone of deep learning and AI workloads.
FP16, bfloat16, and FP8 are reduced-precision formats that offer higher performance and memory efficiency compared to FP32.
The H100's tensor performance is groundbreaking, with up to 1,979 TFLOPS for FP16 and bfloat16 operations, and an massive 3,958 TFLOPS for FP8 operations.
This represents a massive leap from the A100's tensor performance, enabling faster training and inference of large-scale AI models.
The support for lower-precision formats allows users to leverage the trade-off between precision and performance, achieving higher efficiency and faster results in AI workloads.
Memory bandwidth is the rate at which data can be read from or written to the GPU's memory.
It is measured in bytes per second (B/s) and is a critical factor in determining the GPU's performance in memory-intensive workloads.
As highlighted, the H100's HBM3 memory subsystem provides 3 TB/s of memory bandwidth, a significant improvement over the A100's 1.6 TB/s.
This high memory bandwidth enables faster data transfer between the GPU and its memory, reducing latency and improving overall performance.
It is particularly beneficial for workloads that involve large datasets, such as high-resolution video processing, scientific simulations, and training of complex AI models.
NVLink is NVIDIA's proprietary high-speed interconnect technology that enables fast communication between GPUs in a multi-GPU system.
PCIe (Peripheral Component Interconnect Express) is the standard interface for connecting GPUs to the CPU and other components in a computer system.
The H100 supports fourth-generation NVLink, providing up to 900 GB/s of bidirectional bandwidth between two GPUs.
This high-speed interconnect enables efficient data exchange and collaboration between GPUs for scaling up multi-GPU systems.
Additionally, the H100 supports PCIe Gen5, offering up to 128 GB/s of bidirectional bandwidth, doubling the bandwidth of PCIe Gen4.
This increased bandwidth allows for faster data transfer between the GPU and the CPU, reducing bottlenecks and enhancing overall system performance.
TDP (Thermal Design Power) is the maximum amount of heat the GPU is expected to generate under typical workloads, and it determines the cooling requirements for the system.
Power efficiency refers to the GPU's ability to deliver high performance while consuming minimal power.
The H100's TDP ranges from 300W to 700W, depending on the specific model and cooling solution.
While the higher TDP models offer the highest performance, they also require more advanced cooling solutions.
The lower TDP models provide a balance between performance and power consumption, making them suitable for systems with limited power and cooling capacity.
NVIDIA has made significant improvements in power efficiency with the Hopper architecture, enabling the H100 to deliver better performance per watt compared to previous generations.
In summary, the NVIDIA H100 GPU's specifications demonstrate its incredible computational power and memory capabilities. A massive leap up from its predecessor, the A-100,
The NVIDIA H100 GPU is integrated with various NVIDIA technologies and server solutions
NVIDIA AI Enterprise is a suite of software tools and frameworks optimised for AI workloads.
It includes deep learning frameworks, CUDA-X libraries, and NVIDIA's CUDA Toolkit.
The H100 GPU is fully supported by NVIDIA AI Enterprise, enabling development and deployment of AI applications.
NVIDIA AI Enterprise simplifies the installation, management, and scaling of AI infrastructure, making it easier for organisations to adopt and use their H100 GPUs.
Magnum IO is a suite of technologies that optimise I/O performance for accelerated computing.
It includes GPUDirect Storage (GDS) and GPUDirect RDMA (Remote Direct Memory Access).
GDS enables direct data transfer between storage and GPU memory, bypassing the CPU and reducing latency.
GPUDirect RDMA allows direct data transfer between GPUs across different nodes, minimising data movement overhead.
The H100 GPU leverages Magnum IO technologies to maximise I/O performance and efficiency in multi-node environments.
NVIDIA Quantum InfiniBand is a high-performance, low-latency networking solution for AI and HPC workloads.
It enables fast communication between GPUs across multiple nodes, allowing efficient scaling of AI and HPC applications.
The H100 GPU can be used with NVIDIA Quantum InfiniBand to create high-speed, low-latency clusters for distributed AI and HPC workloads.
NVIDIA Quantum InfiniBand's high bandwidth and low latency complement the H100's computational power, enabling efficient scaling and faster time-to-solution.
The NVLink Switch System is a high-speed interconnect that allows multiple GPUs to communicate directly with each other.
It enables up to 256 H100 GPUs to be connected in a high-speed, low-latency fabric.
The NVLink Switch System provides a scalable infrastructure for AI and HPC workloads, allowing seamless scaling of H100 GPU clusters.
With the NVLink Switch System, H100 GPUs can efficiently exchange data and collaborate on large-scale AI and HPC tasks, achieving massive parallelism and performance.
FP64
34 teraFLOPS
26 teraFLOPS
68 teraFLOPS
FP64 Tensor Core
67 teraFLOPS
51 teraFLOPS
134 teraFLOPS
FP32
67 teraFLOPS
51 teraFLOPS
134 teraFLOPS
TF32 Tensor Core
989 teraFLOPS2
756 teraFLOPS2
1,979 teraFLOPS2
BFLOAT16 Tensor Core
1,979 teraFLOPS2
1,513 teraFLOPS2
3,958 teraFLOPS2
FP16 Tensor Core
1,979 teraFLOPS2
1,513 teraFLOPS2
3,958 teraFLOPS2
FP8 Tensor Core
3,958 teraFLOPS2
3,026 teraFLOPS2
7,916 teraFLOPS2
INT8 Tensor Core
3,958 TOPS2
3,026 TOPS2
7,916 TOPS2
GPU memory
80GB
80GB
188GB
GPU memory bandwidth
3.35TB/s
2TB/s
7.8TB/s3
Decoders
7 NVDEC 7 JPEG
7 NVDEC 7 JPEG
14 NVDEC 14 JPEG
Max thermal design power (TDP)
Up to 700W (configurable)
300-350W (configurable)
2x 350-400W (configurable)
Multi-instance GPUs
Up to 7 MIGs @ 10GB each
Up to 7 MIGs @ 10GB each
Up to 14 MIGs @ 12GB each
Form factor
SXM
PCIe > dual-slot > air-cooled
2x PCIe > dual-slot > air-cooled
Interconnect
NVLink: > 900GB/s PCIe > Gen5: 128GB/s
NVLink: > 600GB/s PCIe > Gen5: 128GB/s
NVLink: > 600GB/s PCIe > Gen5: 128GB/s
Server options
NVIDIA HGX™ H100 partner and NVIDIA- Certified Systems™ with 4 or 8 GPUs NVIDIA DGX™ H100 with 8 GPUs
Partner and NVIDIA- Certified Systems with 1–8 GPUs
Partner and NVIDIA- Certified Systems with 2-4 pairs
NVIDIA Enterprise Add-on
Included
Included
H100 SXM: Uses the SXM (Scalable Link Interface) form factor.
H100 PCIe: Uses the PCIe (Peripheral Component Interconnect Express) form factor with a dual-slot, air-cooled design.
H100 NVL1: Uses two PCIe cards with a dual-slot, air-cooled design.
The IEEE 754 standard, officially known as IEEE Standard for Floating-Point Arithmetic, is a technical standard for floating-point computation established by the Institute of Electrical and Electronics Engineers (IEEE).
The standard was first published in 1985 and has since undergone revisions to include more features and accommodate advancements in computing technology. The most significant revisions were made in 2008, and it's often referred to based on this version as IEEE 754-2008.
The primary goal of IEEE 754 is to provide a uniform standard for floating-point arithmetic.
Before this standard, many different floating-point implementations could lead to discrepancies in calculations across different systems. This variability was problematic, especially for applications requiring consistent and reliable results, such as scientific computations.
IEEE 754 addresses these issues by defining:
Formats for Number Representation
Binary formats: These include single precision (32-bit), double precision (64-bit), and extended precision (which can be 80-bit or more).
Decimal formats: Introduced in the 2008 revision, these are useful in financial computations where decimal rounding precision is required.
Arithmetic Operations
The standard specifies the results of arithmetic operations like addition, subtraction, multiplication, division, square root, and remainder. It also includes rounding rules and handling of exceptional cases like division by zero and overflow.
Rounding Rules
IEEE 754 defines several rounding modes to nearest value, towards zero, and towards positive or negative infinity. This is crucial for ensuring that floating-point operations can be consistently replicated across different computing platforms and environments.
Handling of Special Cases
The standard provides a detailed mechanism for dealing with special values like infinity (positive and negative), NaNs (Not a Number), and denormalised numbers. Handling these special cases ensures that the floating-point operations do not crash unexpectedly and provide meaningful outputs even under exceptional conditions.
Normalised and Denormalised Numbers: Normalised numbers have a normalised mantissa where the most significant digit is non-zero. Denormalised numbers allow for representation of numbers closer to zero than would otherwise be possible with normalised representations.
Special Numbers:
Infinities: Positive and negative infinities are used to represent results of operations that exceed the maximum representable value.
Zero: IEEE 754 makes a distinction between positive and negative zeros, which can be relevant in certain mathematical operations.
The adoption of IEEE 754 has had a profound impact on the reliability and portability of software:
Consistency: Programs that use IEEE 754 floating-point arithmetic can expect consistent results across compliant systems, crucial for software portability and reproducibility of results.
Optimisation: Hardware manufacturers have optimised their processors to efficiently handle IEEE 754 operations, leading to improved performance of applications relying on floating-point calculations.
Software Development: The clear rules and definitions provided by IEEE 754 have simplified the development of numerical applications, as developers can rely on standardized behavior of floating-point arithmetic.
Overall, IEEE 754 continues to be a fundamental standard in the computing world, particularly valuable in fields like scientific computing, engineering, and finance, where precision and correctness of numerical computations are critical.
The terms mantissa, exponent, and sign bit are components of the floating-point representation of numbers, as defined by the IEEE 754 standard for floating-point arithmetic.
Each of these components plays a role in how numbers are stored and processed in computers, particularly in the area of scientific calculations where a wide range of values and precision is necessary.
Let’s explore each of these components:
The mantissa, also known as the significand, is the part of a floating-point number that contains its significant digits. In the context of the binary systems used in computers:
Function: The mantissa represents the precision of the number and essentially carries the "actual" digits of the number. For a given floating-point number, the mantissa represents the number's digits in a scaled format.
Details: In a normalised floating-point number, the mantissa is adjusted so the first digit is always a 1 (except in the case of denormalised numbers, where it can be 0). This digit is not stored (known as the "hidden bit" technique) in many floating-point representations to save space, effectively giving an extra bit of precision.
The exponent in a floating-point representation scales the mantissa to provide a very large or very small range of values.
Function: The exponent determines the scale of the number, effectively shifting the decimal (or binary) point to the right or left. This allows floating-point formats to represent very large or very small numbers compactly.
Details: The exponent is stored with a bias in binary systems. For example, an 8-bit exponent in IEEE 754 single-precision floating-point format is stored with a bias of 127. The actual exponent value is calculated by subtracting 127 from the stored exponent value. This bias allows the representation of both positive and negative exponents.
The sign bit is the simplest of the three; it indicates the sign of the number.
Function: It tells whether the number is positive or negative.
Details: In floating-point formats, a sign bit of 0 usually represents a positive number, and a sign bit of 1 represents a negative number.
Consider a 32-bit single-precision floating-point number under IEEE 754:
Sign bit: 1 bit
Exponent: 8 bits (with a bias of 127)
Mantissa: 23 bits (plus 1 hidden bit)
For example, a binary floating-point number could look something like this:
Sign bit: 0
Mantissa: 10100000000000000000000 (where the leading 1 is the hidden bit)
Understanding these components is fundamental for software development and hardware design involving floating-point arithmetic, ensuring precise and efficient numerical computations.
Definition: This is the maximum number of double-precision floating-point operations per second, measured in teraflops (TFLOPS). Double precision (64-bit) offers high accuracy by using 52 bits for the mantissa, 11 bits for the exponent, and 1 sign bit.
Importance: It is crucial for scientific computing and engineering simulations that require high numerical precision to ensure the correctness of results.
Definition: This measures the same as Peak FP64 but specifically using the Tensor Cores, specialised processing units within NVIDIA GPUs designed to accelerate deep learning tasks.
Importance: Provides enhanced performance for certain types of calculations, such as those involving matrices and deep learning models, leveraging optimised hardware.
Definition: The maximum number of single-precision floating-point operations per second. Single precision (32-bit) uses 23 bits for the mantissa, 8 bits for the exponent, and 1 sign bit.
Importance: Balances precision and performance. It is widely used in gaming, graphics rendering, and machine learning where high precision is less critical than performance.
Definition: The maximum number of half-precision floating-point operations per second. Half precision (16-bit) allocates 10 bits to the mantissa, 5 bits to the exponent, and 1 sign bit.
Importance: Offers a good compromise between storage space and precision, suitable for mobile devices, image processing, and certain types of machine learning models where high precision is less necessary.
Definition: The maximum number of bfloat16 floating-point operations per second. Bfloat16 is a truncated floating point format that uses the same 8-bit exponent as FP32 but with a shorter 7-bit mantissa.
Importance: Particularly useful in machine learning and deep learning, providing near-single precision range with reduced precision, which is typically sufficient for these applications.
Definition: This is a specialised metric for the performance of Tensor Float 32 operations per second using Tensor Cores. TF32 is designed to provide the range of FP32 operations while delivering the performance of FP16.
Importance: Critical for AI training tasks, offering a balance of performance and accuracy, enhanced by hardware acceleration.
Definition: Measures the performance of half-precision operations using Tensor Cores, potentially with and without the use of Sparsity.
Importance: Enhances the computational speed for tasks that can tolerate reduced precision, with sparsity providing additional performance gains by skipping zero values in data.
Definition: Similar to Peak BF16 but specifically using Tensor Cores, again with potential variations for sparsity.
Importance: Optimises performance for AI workloads, allowing for faster training times and efficient model deployment.
Definition: This measures the performance of 8-bit floating-point operations per second using Tensor Cores, designed to provide even lower precision with extremely high throughput.
Importance: Useful in scenarios where ultra-high volume computations with lower accuracy requirements are needed, such as certain inference tasks in deep learning.
Definition: The maximum number of 8-bit integer operations per second using Tensor Cores. This format is common in deep learning inference where high precision is not necessary.
Importance: Allows for rapid computation in large-scale and real-time applications, like video processing and real-time AI services, with significant acceleration when using sparsity.
Each of these performance metrics highlights a trade-off between precision and speed, where the choice of number type depends on the specific requirements of the application, such as the need for accuracy versus the need for fast processing and reduced memory usage.
It represents whole numbers (positive, negative or zero) within the range of to
The smallest value for a 32-bit integer is , which equals −2,147,483,648
The largest value for a 32-bit integer is , which equals 2,147,483,647.
NaN (Not a Number): Used to represent undefined or unrepresentable values, such as or the square root of a negative number.
Exponent: 10000001 (which represents 129 in decimal; with bias subtracted, it becomes )
This number represents in binary, which translates into a decimal number after calculating the binary to decimal conversion of the mantissa and applying the exponent as the power of two.