H100 FP16 Tensor Core has 3x throughput compared to A100 FP16 Tensor Core
Taiwan is home to more than 90% of the manufacturing capacity for the world’s most advanced semiconductors.. Pictured here is a TSMC building in Taiwan
What are these different data types?
The terms **INT32**, **FP32**, and **FP64** refer to different data types and their corresponding arithmetic units within the GPU architecture. **INT32** * INT32 stands for **32-bit integer data type**. * It represents whole numbers (positive, negative or zero) within the range of $$-2^{31}$$to $$2^{31}$$ * The smallest value for a 32-bit integer is $$-2^{31}$$, which equals **−2,147,483,648** * The largest value for a 32-bit integer is $$2^{31}$$, which equals **2,147,483,647.** * INT32 units in GPUs are designed to perform integer arithmetic operations, such as addition, subtraction, multiplication, and division on 32-bit integers. * These units are particularly useful for tasks that require precise integer calculations, such as indexing, addressing, and certain computer graphics operations. **FP32 (CUDA cores)** * FP32 stands for **32-bit floating-point data type**, also known as single-precision floating-point. * It follows the IEEE 754 standard for floating-point arithmetic. * FP32 numbers have a significand (mantissa) of 24 bits, an exponent of 8 bits, and a sign bit, allowing for a wide range of representable values. * FP32 units, often referred to as CUDA cores in NVIDIA GPUs, are specialised arithmetic units designed to perform single-precision floating-point operations. * These units are crucial for many computational tasks, including graphics rendering, scientific simulations, and machine learning, where high precision is not always necessary, and the focus is on performance and memory efficiency. **FP64** * FP64 stands for **64-bit floating-point data type**, also known as double-precision floating-point. * It also follows the IEEE 754 standard but ***provides higher precision*** and a wider range of representable values compared to FP32. * FP64 numbers have a significand of 53 bits, an exponent of 11 bits, and a sign bit. * FP64 units in GPUs are designed to perform double-precision floating-point arithmetic operations. * These units are essential for scientific and engineering applications that require high accuracy, such as computational fluid dynamics, finite element analysis, and certain deep learning models. The presence of INT32, FP32, and FP64 units within the Streaming Multiprocessors (SMs) of a GPU allows for efficient execution of various types of arithmetic operations. The SMs are the fundamental processing units of a GPU, and they contain multiple arithmetic units ***working in parallel to achieve high throughput***. The ratio and number of these arithmetic units within an SM can vary depending on the GPU architecture and the intended target applications. For example, GPUs designed for gaming and graphics rendering may have a higher ratio of FP32 units to FP64 units, as single-precision is often sufficient for these tasks. On the other hand, GPUs aimed at scientific computing and simulation may have a more balanced ratio or even a higher number of FP64 units to cater to the demands of double-precision computations. The availability of these different arithmetic units allows developers to optimise their algorithms and computations based on the specific requirements of their applications. By carefully mapping the computational tasks to the appropriate data types and using the corresponding arithmetic units, developers can achieve optimal performance and efficiency on GPUs.What are Ray Tracing Cores (RT Cores)?
Ray tracing cores (RT Cores) are dedicated hardware units within NVIDIA GPUs that are specifically designed to accelerate ray tracing operations. Ray tracing is a **rendering technique** that simulates the ***physical behavior of light*** by tracing the path of rays as they interact with objects in a virtual scene. RT Cores work in conjunction with NVIDIA's RTX software to enable real-time ray tracing in graphics applications. Practical applications of RT Cores and real-time ray tracing include: **Photorealistic rendering:** RT Cores allow developers to create highly realistic scenes with physically accurate lighting, shadows, reflections, and global illumination. This enhances the visual fidelity of games, architectural visualisations, product designs, and other graphics-intensive applications. **Real-time global illumination:** NVIDIA's RTX Global Illumination (RTXGI) technology leverages RT Cores to provide multi-bounce indirect lighting in real-time without the need for time-consuming baking processes or expensive per-frame computations. **Real-time dynamic illumination:** RTX Dynamic Illumination (RTXDI) uses RT Cores to enable the rendering of millions of dynamic lights in real-time, enhancing the realism of night and indoor scenes with a high number of light sources. **Improved performance and scalability:** RT Cores offload ray tracing computations from the main GPU cores, allowing for efficient execution of ray tracing operations. This enables developers to incorporate ray tracing into their applications while maintaining real-time performance, even with limited rays per pixel. **Integration with AI-based techniques:** RT Cores can be used in combination with AI-based techniques like NVIDIA DLSS (Deep Learning Super Sampling) to further improve performance and image quality. DLSS uses deep learning to reconstruct higher-resolution images from lower-resolution inputs, reducing the computational burden on the GPU. **Enhanced visual effects:** Ray tracing enables the creation of realistic visual effects such as accurate reflections, refractions, and translucency. RT Cores accelerate these computations, allowing developers to incorporate these effects into their applications without sacrificing performance. In summary, RT Cores are specialised hardware units in NVIDIA GPUs that accelerate ray tracing operations, enabling real-time ray tracing in various graphics applications. They offer benefits such as photorealistic rendering, real-time global illumination, dynamic lighting, improved performance and scalability, integration with AI-based techniques, and enhanced visual effects. RT Cores have practical applications in gaming, architectural visualisation, product design, and other domains where high-quality, real-time graphics are essential.SMs (Streaming Multiprocessors)
DPX instructions accelerate dynamic programming
Asynchronous execution concurrency and enhancements in NVIDIA Hopper
An detailed explanation of Cooperative Groups in CUDA
Cooperative Groups is an **extension to the CUDA programming model** that allows developers to organise groups of threads that can communicate and synchronise with each other. It provides a way to express the granularity at which threads are cooperating, enabling richer and more efficient parallel patterns. Traditionally, CUDA programming relied on a single construct for synchronising threads: **the \_\_syncthreads() function**, which creates a barrier across all threads within a thread block. However, developers often needed more flexibility to define and synchronise groups of threads at different granularities to achieve better performance and design flexibility. **Relation to the GPU** In CUDA, ***the GPU executes threads in groups called warps*** (typically 32 threads per warp). Warps are further organised into thread blocks, which can contain multiple warps. Thread blocks are then grouped into a grid, which represents the entire kernel launch. **Cooperative Groups** allows developers to work with these different levels of thread hierarchy and define their own groups of threads for synchronisation and communication purposes. It provides a way to express the cooperation among threads at the warp level, thread block level, or even across multiple thread blocks. **Key Concepts in Cooperative Groups** **Thread Groups:** Cooperative Groups introduces the concept of thread groups, which are objects that represent a set of threads that can cooperate. Thread groups can be created based on the existing CUDA thread hierarchy (e.g., thread blocks) or by partitioning larger groups into smaller subgroups. **Synchronisation:** Cooperative Groups provides synchronisation primitives, such as group-wide barriers (e.g., thread\_group::sync()), which allow threads within a group to synchronise and ensure that all threads have reached a certain point before proceeding. **Collective Operations:** Cooperative Groups supports collective operations, such as reductions (e.g., reduce()) and scans (e.g., exclusive\_scan()), which perform operations across all threads in a group. These operations can take advantage of hardware acceleration on supported devices. **Partitioning:** Cooperative Groups allows partitioning larger thread groups into smaller subgroups using operations like tiled\_partition(). This enables developers to divide the workload among subgroups and perform more fine-grained synchronisation and communication. **Optimisation with Cooperative Groups** Cooperative Groups can be used to optimise CUDA code in several ways: **Improved Synchronisation:** By using group-wide synchronisation primitives instead of global barriers, developers can minimise the synchronisation overhead and **avoid unnecessary waiting for threads** that are not involved in a particular operation. **Data Locality:** Cooperative Groups allows developers to express data locality by partitioning thread groups and assigning specific tasks to subgroups. This can lead to **better cache utilisation and reduced memory access latency**. **Parallel Reduction:** Collective operations like reduce() can be used to **perform efficient parallel reductions** within a group of threads. This can significantly speed up operations that involve aggregating values across threads. **Fine-Grained Parallelism:** By partitioning thread groups into smaller subgroups, developers can **exploit fine-grained parallelism** and distribute the workload more effectively across the available GPU resources. **Warp-Level Primitives:** Cooperative Groups provides warp-level primitives, such as shuffle operations, which **enable efficient communication and data exchange among threads** within a warp. These primitives can be used to optimise algorithms that require data sharing and collaboration among threads. **Example Use Case** Let's consider a scenario where you have a large array of data, and you want to perform a parallel reduction to calculate the sum of all elements. With Cooperative Groups, you can partition the thread block into smaller subgroups (e.g., tiles of 32 threads) and perform the reduction within each subgroup using the reduce() operation. Then, you can further reduce the partial sums from each subgroup to obtain the final result. This approach can lead to faster and more efficient parallel reduction compared to a naïve implementation that relies solely on global barriers. **Conclusion** Cooperative Groups is a powerful extension to the CUDA programming model that enables developers to express thread cooperation and synchronisation at different granularities. By leveraging the concepts of thread groups, synchronisation primitives, and collective operations, developers can optimise their CUDA code for better performance, data locality, and parallel efficiency. Cooperative Groups allows for fine-grained control over thread collaboration, enabling more sophisticated parallel patterns and algorithms on the GPU. It's important to note that the effective use of Cooperative Groups requires careful consideration of the problem at hand and the specific GPU architecture being targeted. Developers should experiment with different group sizes, partitioning strategies, and collective operations to find the optimal configuration for their specific use case. Overall, Cooperative Groups provides a flexible and expressive way to harness the power of GPU parallelism, allowing developers to write more efficient and scalable CUDA code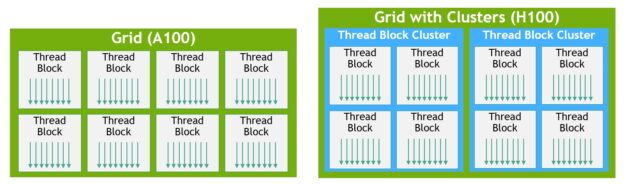
Thread block clusters and grids with clusters
MIG can partition the GPU into as many as seven instances, each fully isolated with its own high-bandwidth memory, cache, and compute cores